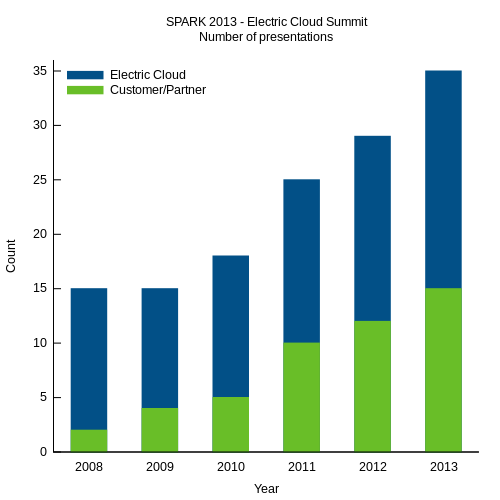
A while back I posted a series of articles exploring the scalability of SCons, a popular Python-based build tool. In a nutshell, my experiments showed that SCons exhibits roughly quadratic growth in build runtimes as the number of targets increases:
Recently Dirk Baechle attempted to rebut my findings in an entry on the SCons wiki: Why SCons is not slow. I thought Dirk made some credible suggestions that could explain my results, and he did some smart things in his effort to invalidate my results. Unfortunately, his methods were flawed and his conclusions are invalid. My original results still stand: SCons really is slow. In the sections that follow I’ll share my own updated benchmarks and show where Dirk’s analysis went wrong.
Test setup
As before, I used genscons.pl to generate sample builds ranging from 2,000 to 50,000 targets. However, my test system was much beefier this time:
|
2013 |
2010 |
| OS |
Linux Mint 14 (kernel version 3.5.0-17-generic) |
RedHat Desktop 3 (kernel version 2.4.21-58.ELsmp) |
| CPU |
Quad 1.7GHz Intel Core i7, hyperthreaded |
Dual 2.4GHz Intel Xeon, hyperthreaded |
| RAM |
16 GB |
2 GB |
| HD |
SSD |
(unknown) |
| SCons |
2.3.0 |
1.2.0.r3842 |
| Python |
2.7.3 (system default) |
2.6.2 |
Before running the tests, I rebooted the system to ensure there were no rogue processes consuming memory or CPU. I also forced the CPU cores into “performance” mode to ensure that they ran at their full 1.7GHz speed, rather than at the lower 933MHz they switch to when idle.
Revisiting the original benchmark
I think Dirk had two credible theories to explain the results I obtained in my original tests. First, Dirk wondered if those results may have been the result of virtual memory swapping — my original test system had relatively little RAM, and SCons itself uses a lot of memory. It’s plausible that physical memory was exhausted, forcing the OS to swap memory to disk. As Dirk said, “this would explain the increase of build times” — you bet it would! I don’t remember seeing any indication of memory swapping when I ran these tests originally, but to be honest it was nearly 4 years ago and perhaps my memory is not reliable. To eliminate this possibility, I ran the tests on a system with 16 GB RAM this time. During the tests I ran vmstat 5, which collects memory and swap usage information at five second intervals, and captured the result in a log.
Next, he suggested that I skewed the results by directing SCons to inherit the ambient environment, rather than using SCons’ default “sanitized” environment. That is, he felt I should have used env = Environment() rather than env = Environment(ENV = os.environ). To ensure that this was not a factor, I modified the tests so that they did not inherit the environment. At the same time, I substituted echo for the compiler and other commands, in order to make the tests faster. Besides, I’m not interested in benchmarking the compiler — just SCons! Here’s what my Environment declaration looks like now:
env = Environment(CC = 'echo', AR = 'echo', RANLIB = 'echo')
With these changes in place I reran my benchmarks. As expected, there was no change in the outcome. There is no doubt: SCons does not scale linearly. Instead the growth is polynomial, following an n1.85 curve. And thanks to the the vmstat output we can be certain that there was absolutely no swapping affecting the benchmarks. Here’s a graph of the results, including an n1.85 curve for comparison — notice that you can barely see that curve because it matches the observed data so well!
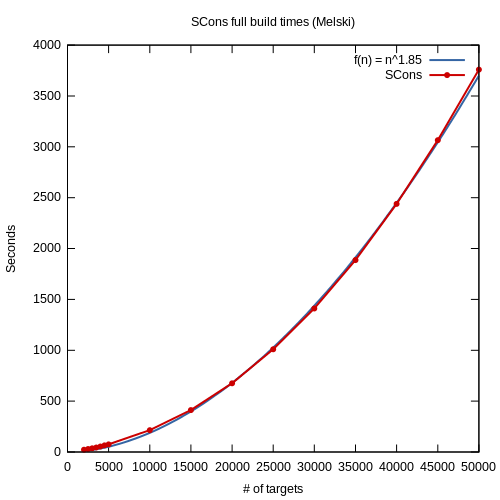
For comparison, I used the SCons build log to make a shell script that executes the same series of echo commands. At 50,000 targets, the shell script ran in 1.097s. You read that right: 1.097s. Granted, the shell script doesn’t do stuff like up-to-date checks, etc., but still — of the 3,759s average SCons runtime, 3,758s — 99.97% — is SCons overhead.
I also created a non-recursive Makefile that “builds” the same targets with the same echo commands. This is a more realistic comparison to SCons — after all, nobody would dream of actually controlling a build with a straight-line shell script, but lots of people would use GNU make to do it. With 50,000 targets, GNU make ran for 82.469s — more than 45 times faster than SCons.
What is linear scaling?
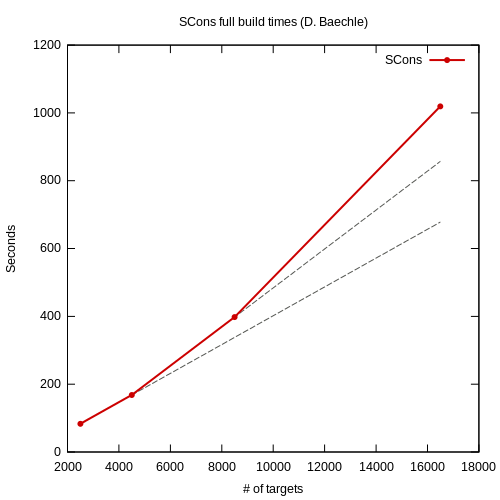
If the performance problems are so obvious, why did Dirk fail to see them? Here’s a graph made from his test results:

Dirk says that this demonstrates “SCons’ linear scaling”. I find this statement baffling, because his data clearly shows that SCons does not scale linearly. It’s simple, really: linear scaling just means that the build time increases by the same amount for each new target you add, regardless of how many targets you already have. Put another way, it means that the difference in build time between 1,000 targets and 2,000 targets is exactly the same as the difference between 10,000 and 11,000 targets, or between 30,000 and 31,000 targets. Or, put yet another way, it means that when you plot the build time versus the number of targets, you should get a straight line with no change in slope at any point. Now you tell me: does that describe Dirk’s graph?
Here’s another version of that graph, this time augmented with a couple additional lines that show what the plot would look like if SCons were truly scaling linearly. The first projection is based on the original graph from 2,500 to 4,500 targets — that is, if we assume that SCons scales linearly and that the increase in build time between 2,500 and 4,500 targets is representative of the cost to add 2,000 more targets, then this line shows us how we should expect the build time to increase. Similarly, the second projection is based on the original graph between 4,500 and 8,500 targets. You can easily see that the actual data does not match either projection. Furthermore you can see that the slope of these projections is increasing:
This shows the importance of testing at large scale when you’re trying to characterize the scalability of a system from empirical data. It can be difficult to differentiate polynomial from logarithmic or linear at low scales, especially once you incorporate the constant factors — polynomial algorithms can sometimes even give better absolute performance for small inputs than linear algorithms! It’s not until you plot enough data points at large enough values, as I’ve done, that it becomes easy to see and identify the curve.
What does profiling tell us?
Next, Dirk reran some of his tests under a profiler, on the very reasonable assumption that if there was a performance problem to be found, it would manifest in the profiling data — surely at least one function would demonstrate a larger-than-expected growth in runtime. Dirk only shared profiling data for two runs, both incremental builds, at 8,500 and 16,500 targets. That’s unfortunate for a couple reasons. First, the performance problem is less apparent on incremental builds than on full builds. Second, with only two datapoints it is literally not possible to determine whether growth is linear or polynomial. The results of Dirk’s profiling was negative: he found no “significant difference or increase” in any function.
Fortunately it’s easy to run this experiment myself. Dirk used cProfile, which is built-in to Python. To profile a Python script you can inject cProfile from the command-line, like this: python -m cProfile scons. Just before Python exits, cProfile dumps timing data for every function invoked during the run. I ran several full builds with the profiler enabled, from 2,000 to 20,000 targets. Then I sorted the profiling data by function internal time (time spent in the function exclusively, not in its descendents). In every run, the same two functions appeared at the top of the list: posix.waitpid and posix.fork. To be honest this was a surprise to me — previously I believed the problem was in SCons’ Taskmaster implementation. But I can’t really argue with the data. It makes sense that SCons would spend most of its time running and waiting for child processes to execute, and even that the amount of time spent in these functions would increase as the number of child processes increases. But look at the growth in runtimes in these two functions:
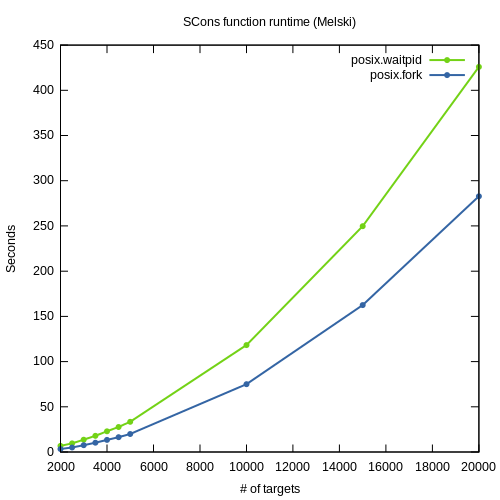
Like the overall build time, these curves are obviously non-linear. Armed with this knowledge, I went back to Dirk’s profiling data. To my surprise, posix.waitpid and posix.fork don’t even appear in Dirk’s data. On closer inspection, his data seems to include only a subset of all functions — about 600 functions, whereas my profiling data contains more than 1,500. I cannot explain this — perhaps Dirk filtered the results to exclude functions that are part of the Python library, assuming that the problem must be in SCons’ own code rather than in the library on which it is built.
This demonstrates a second fundamental principle of performance analysis: make sure that you consider all the data. Programmers’ intuition about performance problems is notoriously bad — even mine! — which is why it’s important to measure before acting. But measuring won’t help if you’re missing critical data or if you discard part of the data before doing any analysis.
Conclusions
On the surface, performance analysis seems like it should be simple: start a timer, run some code, stop the timer. Done correctly, performance analysis can illuminate the dark corners of your application’s performance. Done incorrectly — and there are many ways to do it incorrectly — it can lead you on a wild goose chase and cause you to squander resources fixing the wrong problems.
Dirk Baechle had good intentions when he set out to analyze SCons performance, but he made some mistakes in his process that led him to an erroneous conclusion. First, he didn’t run enough large-scale tests to really see the performance problem. Second, he filtered his experimental data in a way that obscured the existence of the problem. But perhaps his worst mistake was to start with a conclusion — that there is no performance problem — and then look for data to support it, rather than starting with the data and letting it impartially guide him to an evidence-based conclusion.
To me the evidence seems indisputable: SCons exhibits roughly quadratic growth in runtimes as the number of build targets increases, rendering it unusable for large-scale software development (tens of thousands of build outputs). There is no evidence that this is a result of virtual memory swapping. Profiling suggests a possible pair of culprits in posix.waitpid and posix.fork. I leave it to Dirk and the SCons team to investigate further; in the meantime, you can find my test harness and test results in my GitHub repo. If you can see a flaw in my methodology, sound off in the comments!