ElectricAccelerator 7.1 hit the streets a last month, on October 10, just six months after the 7.0 release in April. There are some really cool new features in this release, which picks up right where 7.0 left off by adding even more ground-breaking performance features: schedule optimization and Javadoc caching. Here’s a quick look at each.
Schedule Optimization
The idea behind schedule optimization is really simple: we can reduce overall build duration if we’re smarter about the order in which jobs are run. In essense, it’s about packing the jobs in tighter, eliminating idle time in the middle of the build and reducing the “ragged right edge”. Here’s a side-by-side comparison of the same build, first using normal scheduling and then using schedule optimization. You can easily see that schedule optimization made the second build faster — an 11% improvement in this small, real-world example:
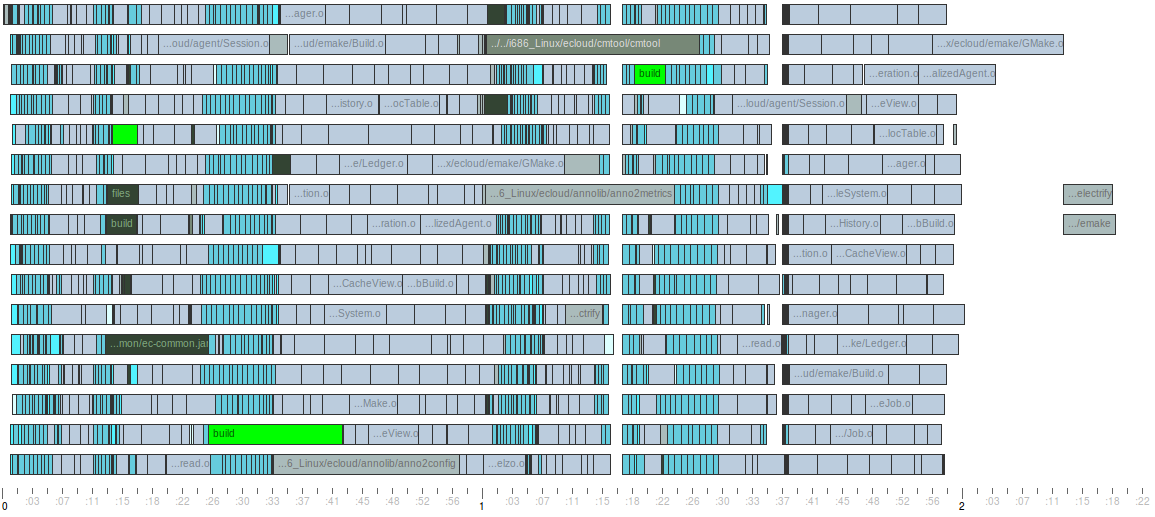
Build using naive scheduling — click to view full size
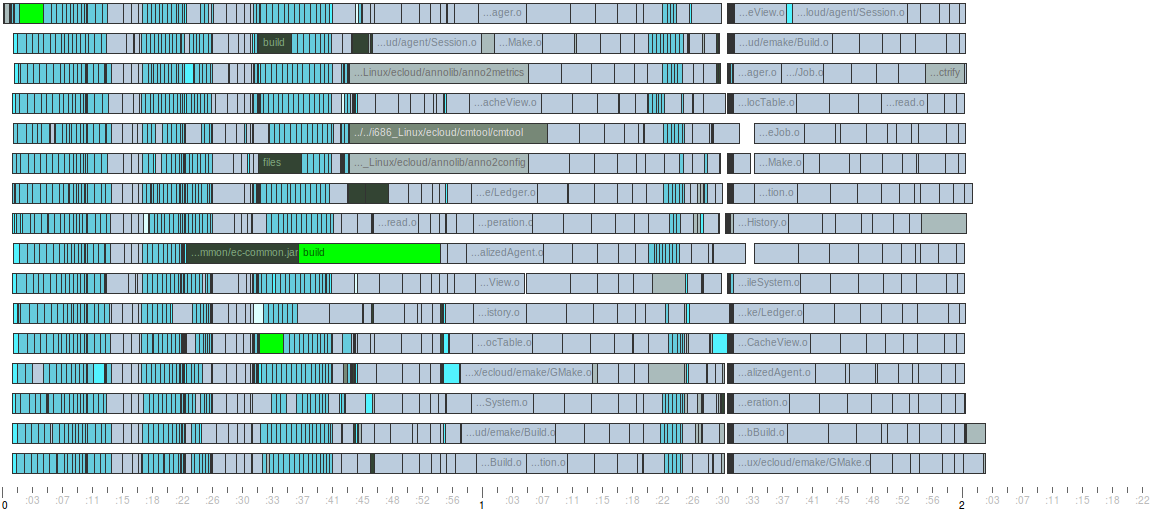
Build using schedule optimization – click to view full size
If you study the two runs more closely, you can see how schedule optimization produced this improvement: key jobs, in particular the longest jobs, were started earlier. As a result, idle time in the middle of the build was reduced or eliminated entirely, and the right edge is much less uneven. But the best part? It’s completely automatic: all you have to do is run the build once for emake to learn its performance profile. Every subsequent build will leverage that data to improve build performance, almost like magic.
Not convinced? Here’s a look at the impact of schedule optimization on another, much bigger proprietary build (serial build time 18h25m). The build is already highly parallelizable and achieves an impressive 37.2x speedup with 48 agents — but schedule optimization can reduce the build duration by nearly 25% more, bringing to total speedup on 48 agents to an eye-popping 47.5x!

Build duration with naive and optimized scheduling
There’s another interesting angle to schedule optimization though. Most people will take the performance gains and use them to get a faster build on the same hardware. But you could go the other direction just as easily — keep the same build duration, but do it with dramatically less hardware. The following graph quantifies the savings, in terms of cores needed to achieve a particular build duration. Suppose we set a target build duration of 30 minutes. With naive scheduling, we’d need 48 agents to meet that target. With schedule optimization, we need only 38.
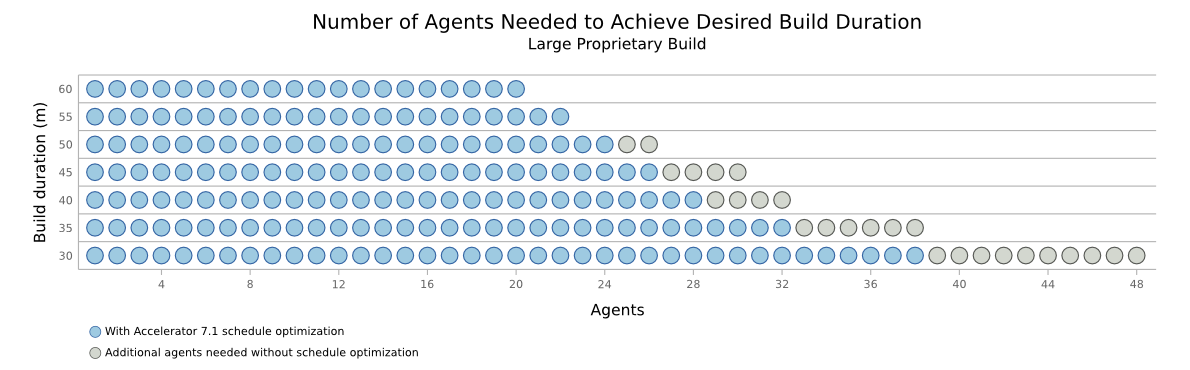
Resource requirements with naive and optimized scheduling – click for full size
I’m really excited about schedule optimization, because it’s one of those rare features that give you something for nothing. It’s also been a long time coming — the idea was originally conceived of over three years ago, and it’s only now that we were able to bring it to fruition.
Schedule optimization works with emake on all supported platforms, with all emulation modes. It is not currently available for use with electrify.
Javadoc caching
The second major feature in Accelerator 7.1 is Javadoc caching. Again, it’s a simple idea: think “ccache”, but for Javadoc instead of compiles. This is the next phase in the evolution of Accelerator’s output reuse initiative, which began in the 7.0 release with parse avoidance. Like any output reuse feature, Javadoc caching works by capturing the product of a Javadoc invocation and storing it in a cache indexed by a hash of the inputs used — including the Java files themselves, the environment variables, and the command-line. In subsequent builds, emake will check those inputs again and if it computes the same hash, emake will used the cached results instead of running Javadoc again. On big Javadoc jobs, this can produce significant savings. For example, in the Android “Jelly Bean” open-source build, the main Javadoc invocation usually takes about five minutes. With Javadoc caching in Accelerator 7.1, that job runs in only about one minute — an 80% reduction! In turn that gives us a full one minute reduction in the overall build time, dropping the build from 13 minutes to 12 — nearly a 10% improvement:

Uncached Javadoc job in Android build – click for full image

Cached Javadoc job in Android build – click for full image
Javadoc caching is available on Solaris and Linux only in Accelerator 7.1.
Looking ahead
I hope you’re as excited about Accelerator 7.1 as I am — for the second time this year, we’re bringing revolutionary new performance features to the table. But of course our work is never done. We’ve been hard at work on the “buddy cluster” concept for the next release of Accelerator. Hopefully I’ll be able to share some screenshots of that here before the end of the year. We’re also exploring acceleration for Bitbake builds like the Yocto Project. And last, but certainly not least, we’ll soon start fleshing out the next phase of output reuse in Accelerator — caching compiler invocations. Stay tuned!
