Recently I spent some time redesigning and optimizing the continuous integration (CI) process used to build and test a large software project which I’ll call ZipGit here. The ZipGit CI process is implemented in CloudBees CD, a powerful general purpose process automation system most often used to implement continuous integration and continuous deployment workflows. I used several common — and a few not-so-common — strategies to slash the time to complete a full CI run on all platforms from over 21 hours to under 3 hours. In this blog I’ll show how you can apply one of those not-so-common strategies, called schedule optimization, to your own CloudBees CD-based processes, and shave double-digit percentages off the elapsed time.
What is schedule optimization?
Schedule optimization is a simple idea: in a resource-constrained environment, you can reduce the total time required to execute the tasks in a parallel workload by intelligently choosing the order in which those tasks are started. Consider a simple example with 4 independent tasks that could be run in parallel:
- Task A takes 17 minutes to complete.
- Task B takes 12 minutes.
- Task C takes 31 minutes.
- Task D takes 65 minutes.
If we have only two resources on which to run these tasks and we naively run them in the order they’re listed above, we can expect that initially task A and task B start in parallel. When task B finishes after 12 minutes, task C starts in its place. When task A finishes after 17 minutes (5 minutes after B), it is replaced by task D. Here’s a quick visualization of this execution order, which makes the problem opportunity clear:
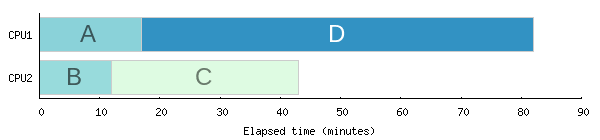
The total elapsed time is 82 minutes — literally the sum of the durations of tasks A and D. But you can easily see that if we rearrange things a bit, we can reduce that elapsed time. When the tasks are truly independent, we need only start them in longest-first order. In this example that means starting tasks D and C first, rather than A and B. When task C finishes at 31 minutes, it is replaced by task A, the next longest task. When task A finishes 17 minutes later, it is replaced by task B. This gives us a significant improvement in the total elapsed time:

With this optimized ordering, all of the tasks are finished after just 65 minutes. That’s a 20% improvement, without adding resources or modifying the tasks themselves in any way! We simply made better use of the resources we had available. This is the central idea of schedule optimization: be smarter about the order in which a set of parallelizable tasks are started in order to reduce the total elapsed time required to complete those tasks.
Note that schedule optimization has no effect if you have only one resource and can thus run only one task at a time. Likewise schedule optimization has no effect if you have as many resources as you do tasks — in that case, you can just run all the tasks at once, and the total runtime will naturally be as long as the single longest task.
Finally, note that if there are dependencies between the tasks then schedule optimization is considerably more difficult as it requires a deep understanding of those dependencies to do correctly. I won’t get into that more complex scenario here; fortunately, in the ZipGit CI process and many other real-world examples, you really do have a collection of independent tasks, so the simple longest-first algorithm works well.
Optimization opportunities in ZipGit CI
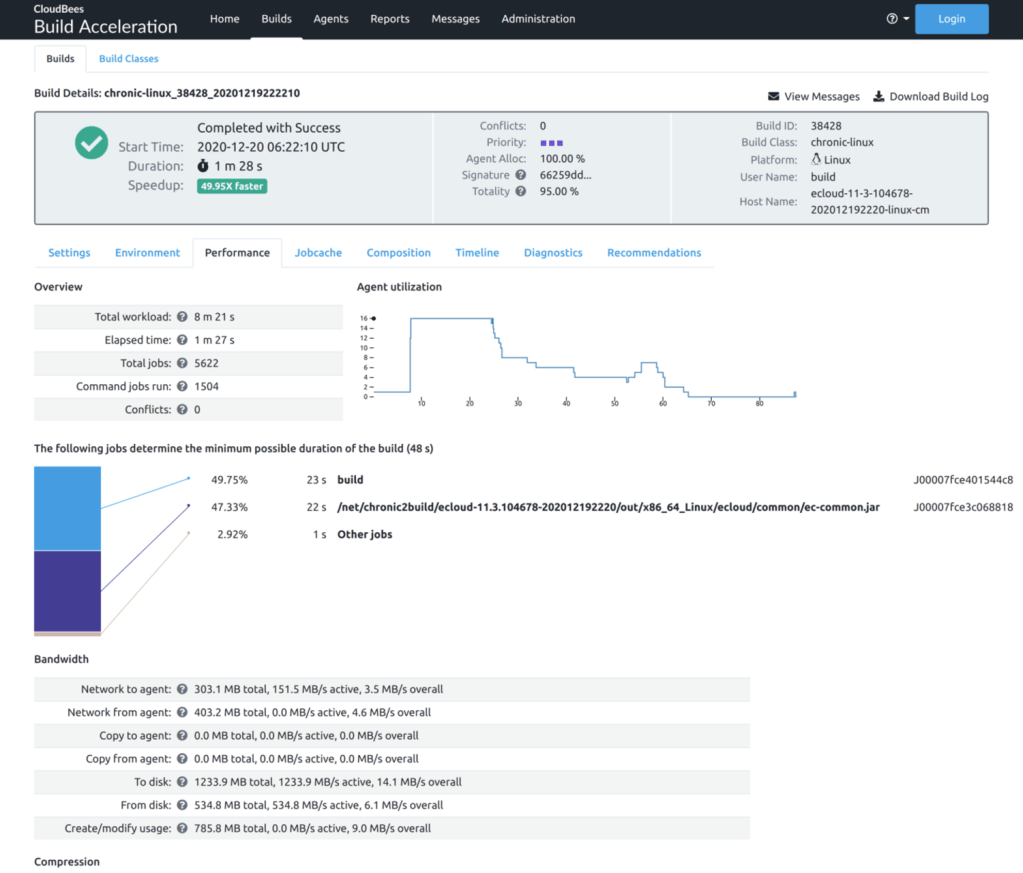
After adopting parallel execution throughout the ZipGit CI process I noticed a set of steps that was an ideal candidate for schedule optimization: the system tests. Running these 16 independent test steps in parallel on a pool of 6 resources already reduced the duration more than 4x, from over 6 hours to 1½ hours:

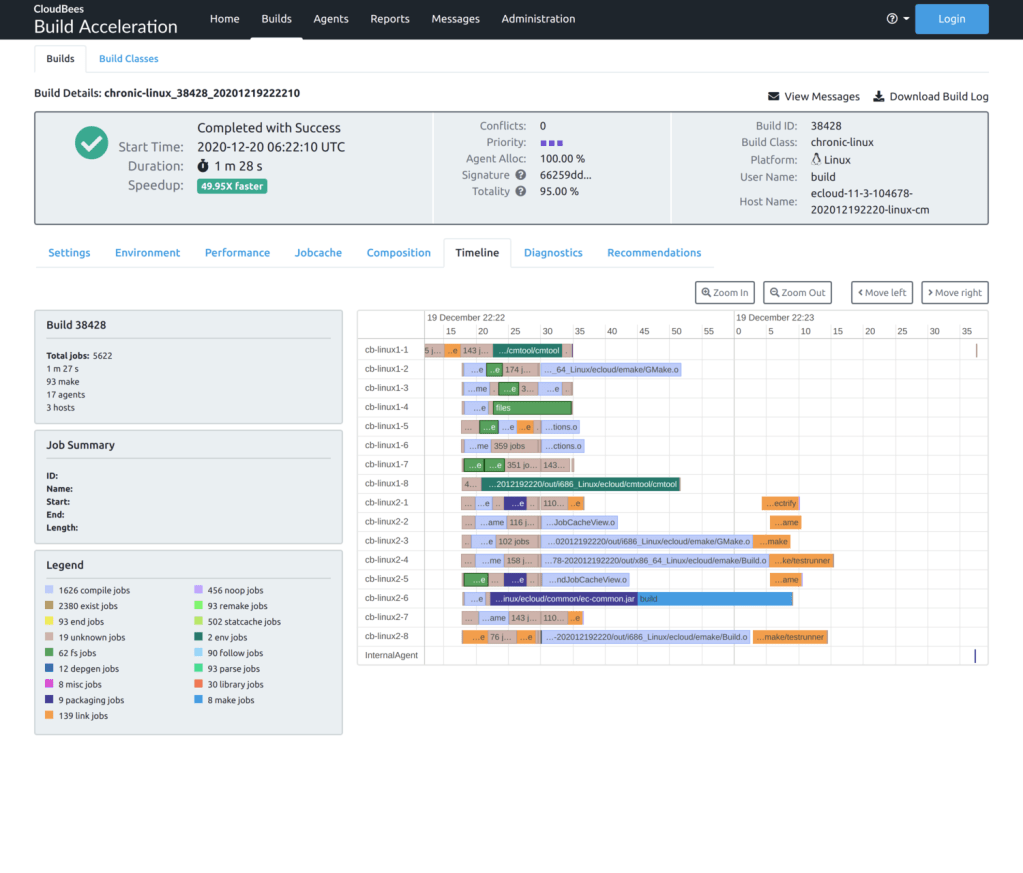
The total elapsed time is shown in the top row here: 01:30:45.756. That’s a terrific improvement from the original 6+ hours! But because CloudBees CD dispatches parallel steps in declaration order, or literally the order in which the steps are specified in the procedure definition, the overall execution time is not optimal. You can see in the details view that several long steps happen to be near the end of the list, like the Platform and History test suites. Because they’re listed near the end, they will get started later in the process. Indeed if we visualize the execution of all of the system test steps, the inefficiency is easily seen:
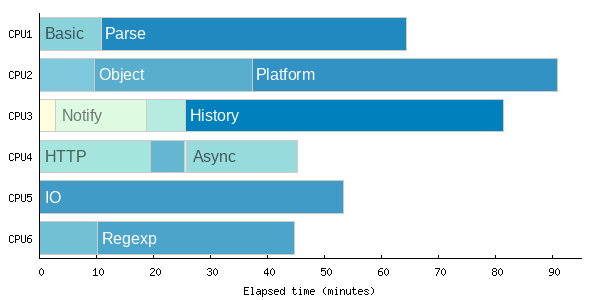
Adaptive Schedule Optimization in CloudBees CD
Obviously we could manually reorder the steps in the procedure definition to eliminate this inefficiency — and for some use cases that will be the easiest and most expedient solution! But I find that approach tedious, error prone, and undesirable because it will not adapt to changes in the duration of the steps. Instead, we can use CloudBees CD properties and the CloudBees CD Perl API to dynamically adjust the order on every run of the CI process, so that we always get optimal results. In essence, we can build a dynamic, adaptive schedule optimizer.
To begin, we have to create a new Command step, then set the Shell option to ec-perl:

Now we just need to write some Perl code to determine the correct ordering and create the steps in that order — remember, CloudBees CD will start the steps in declaration order, so we just have to make sure they are declared in our preferred order! I’m going to show each piece of the implementation separately so I can explain what’s going on, but ultimately all of this code will go in the Command(s) field of the step we’re creating:

I’ve already added the boilerplate declarations that I use in any ec-perl script. Next we’ll create a list that contains enough information for us to actually create the steps later. We’ll use this list to define the ordering of the steps. For each step we define a few attributes:
- name: a unique, memorable identifier for the step. This will be used later to find historical timing data for the step.
- label: a display name for the step. This will be shown in the UI when viewing the job details.
- command: the actual commands to run for the step. In ZipGit most of the system test steps actually have roughly the same invocation so this is straightforward, but some have different requirements as you can see. In your processes obviously you can make the commands as complex as you like, even defining the commands for each step individually if necessary.
my @steps = ();
# Most system tests use the same invocation commands, parameterized.
# Add those to @steps.
foreach ("Basic", "Parse", "Event", "Object",
"Platform", "Compile", "Notify", "Registry",
"History", "List", "Interp", "Async",
"IO", "Format", "Regexp") {
my $name = $_;
push @steps, { name => $name,
label => $name . " tests",
command => "gmake -C src test SUITE=" . lc($name) };
}
# HTTP tests requires that we start a test HTTP server before running the
# tests, so we can't handle it in the loop above. Add it now.
my $httpCommand = <<"END_COMMAND";
./scripts/startHTTP.sh 8080 \\
&& gmake -C src test SUITE=http TESTPORT=8080 \\
&& ./scripts/stopHTTP.sh 8080
END_COMMAND
push @steps, { name => "HTTP",
label => "HTTP tests",
command => $httpCommand };With the list of steps initialized, we can fetch historical timing data for each step. To facilitate this I used a property sheet on the project containing a property that tracks the historical runtime for each test step, at whole second resolution. Here we simply fetch the current value and add it to the step descriptions. If there is no historical data for a step, a value of zero is used. This makes the implementation robust in the face of changes to the set of steps being run:
# Get historical timing data for each step.
foreach my $step (@steps) {
my $length = 0;
my $lengthProperty = $ec->getProperty("/myProject/systemtest/$step->{name}");
if ($lengthProperty) {
my $lengthString = $lengthProperty->findvalue("//value");
if (length $lengthString) {
$length = int($lengthString);
}
}
$step->{length} = $length;
}Once we have the historical length data, we simply sort the steps according to their length, so the longest is first:
# Sort the steps by decreasing length, so the longest step is first.
@steps = sort { $b->{length} <=> $a->{length} } @steps;Now we just create the steps in the order we’ve computed, using the createJobStep API. In addition, for each step we append commands to update the timing data upon the successful completion of the step. You can use whatever policy you like to decide how to update the data; in this case I chose to give greater weight to the historical data to help compensate for minor fluctuations in the runtime from one run to the next. Note that all of the steps created will be children of the step running this Perl code, and that we are careful to mark them as eligible for parallel execution. Finally note what seems like an insane amount of backslashes in the update commands! That’s because we have to escape things first for Perl, but also for the shell that will ultimately execute those commands:
# Create the steps to run the actual tests, with some extra code to handle
# updating the historical timing data when the tests finish successfully.
foreach my $step (@steps) {
my $updateCommand = <<"END_UPDATE_COMMAND";
if [ \$? = 0 ] ; then
echo "Step succeeded, updating timing data."
TIMING_PROPERTY="/myProject/systemtest/$step->{name}"
LENGTH=`ectool getProperty /myJobStep/elapsedTime`
OLD_LENGTH=`ectool getProperty "\$TIMING_PROPERTY" 2> /dev/null`
if [ -z "\$OLD_LENGTH" ] ; then
ectool createProperty "\$TIMING_PROPERTY" --suppressValueTracking 1
NEW_LENGTH=\$(expr \$LENGTH / 1000)
else
NEW_LENGTH=\$(expr \\( \\( \$OLD_LENGTH \\* 4 \\) + \\( \$LENGTH / 1000
\\) \\) / 5 )
fi
ectool setProperty "\$TIMING_PROPERTY" "\$NEW_LENGTH" --suppressValueTrackin
g 1
else
echo "Step failed, skipping timing update."
fi
END_UPDATE_COMMAND
$ec->createJobStep({
jobStepId => $ENV{COMMANDER_JOBSTEPID},
jobStepName => "$step->{label}",
resourceName => "systemtest-pool",
parallel => 1,
command => $step->{command} . $updateCommand,
shell => "sh",
logFileName => "systemtest-$step->{name}.log",
postProcessor => "postp",
timeLimit => "90",
timeLimitUnits => 'minutes'
});
}And that’s it! All that remains is to delete (or disable) the original manually created steps for running the tests and give our new mechanism a try. Note that on the first trial run the schedule order will not be optimized, because we haven’t yet populated the historical runtime data for the steps. You could bootstrap the process by manually creating the properties with that information, or you could just run the process twice — once to learn the step durations, and a second time to use that data to optimize the schedule. In the ZipGit CI process, applying schedule optimization to the system test steps cut the execution time from 90 minutes to about 64 minutes, a 29% improvement!
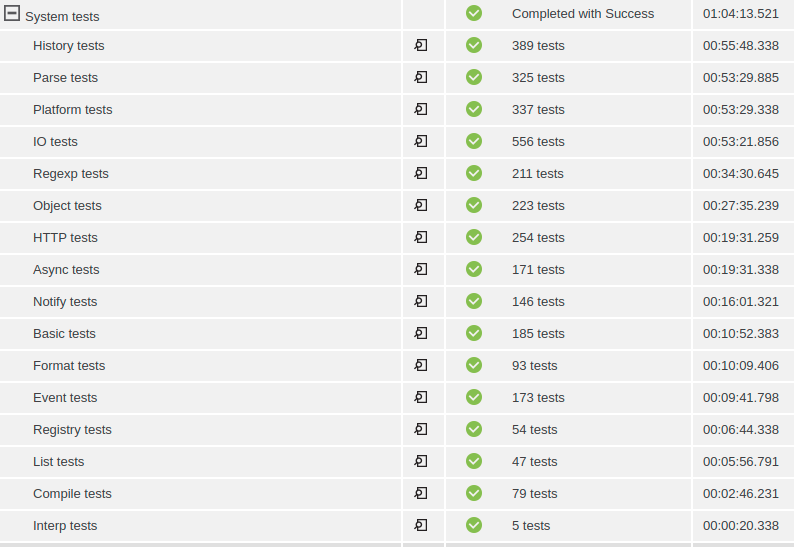
And as expected, when we graph the execution of these steps everything is neatly packed. With schedule optimization enabled, we make the most efficient possible use of the pool of resources:

Final thoughts
Schedule optimization is a powerful technique that allows you to squeeze the absolute best performance out of a resource constrained environment — and let’s be honest, what environment isn’t resource constrained? With minimal effort you can ensure ideal utilization of your resources, cutting both your wait time and your cost-per-build. CloudBees CD makes it easy, with durable storage in the form of properties and property sheets, and a powerful Perl API for dynamic step creation. I hope this has inspired you to try schedule optimization in your own CI processes!