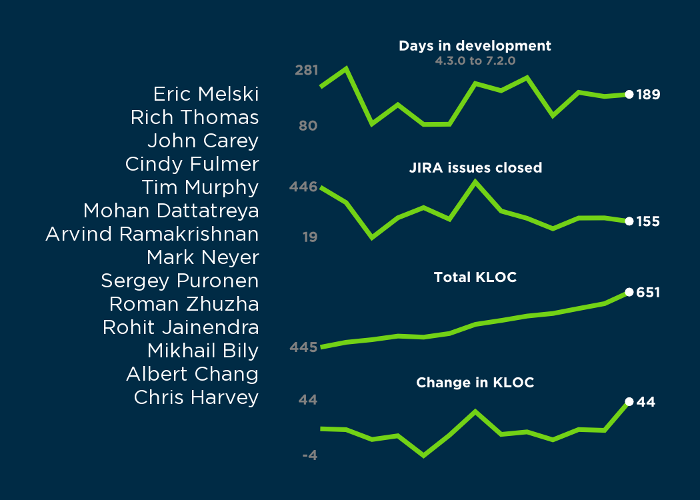
We recently released ElectricAccelerator 9.1, the 33rd feature release in the product’s 15-year-and-counting development history. This release includes several enhancements which I’m pleased to share with you: a new look-and-feel, improved scalability, and a new flexible licensing system to accommodate small- and medium-sized teams! Read on for more details.
Cluster Manager Dashboard
The most visible change in 9.1 is the all-new Cluster Manager dashboard, which collects several pieces of information about the health and performance of your cluster in what we hope will be a one-stop-shop for cluster monitoring. We tried to pack in a lot of usable data, while maintaining the clean look-and-feel that is the hallmark of the new Cluster Manager interface:

The top of the dashboard will look familiar if you ever tried ElectricAccelerator Huddle, where the metrics proved so popular with users that we decided to surface them in the standard Accelerator UI as well. Across the top of the page you’ll find the following information:
|
|
|
| Agents | The total number of agents in the cluster. If any are offline, a warning icon is shown next to the count. Clicking the icon will show you the bad agents. |
| Running builds | Number of builds currently in progress. |
| CPU Hours Used | The total CPU time used by all builds ever run on the cluster. For example, a build that used 10 agents for 1 hour used a total of 10 CPU-hours. |
| Developer Hours Saved | The total time saved by using Accelerator. For example, if your build takes 10 hours when run serially but just 1 hour with Accelerator, you save 9 hours each time you run that build. |
| Days Remaining | Number of days until your license expires — so you know when to renew. |
|
Below the row of metrics the dashboard is in two columns. On the left you’ll find these sections:
Welcome: a brief description of the major new features in the release you’re using, as well as information about new releases if you’re not running the latest version. Online Resources: links to sources of help like the ElectricAccelerator Knowledge Base and Ask Electric Cloud, our community Q&A site. Lightning Lessons: short tutorials and demos to help new users get started using ElectricAccelerator to crush build times. |
|
Finally, in the right-hand column of the dashboard you’ll find some preset reports:
Agent Usage: this graph shows agent availability and demand over the past 24 hours, so you can quickly see if usage has exceeded capacity, indicating that you need to expand your cluster. Build Duration: here you’ll see the duration of every build run in the past 24 hours, colored according to build class, so you can easily spot aberations. Clicking any of the data points will take you to the details page for that build. |
|
Clean, Modern Cluster Manager Interface
As excited as I am about the new Cluster Manager dashboard, the user interface updates don’t end there. We’ve overhauled the entire CM UI, the first complete overhaul since version 4.0 in 2007. With this release the UI has a modernized look-and-feel, and uses the same visual design elements as ElectricFlow — so we have a consistent design language across Electric Cloud’s suite of products. Functionally the UI is not much changed, although filters are a bit more flexible and easier to use. Rather than belabor the point, take a look at these screenshots of the Builds and Agents pages:


Back-end Updates: Java 8 and 64-bit
Accelerator 9.1 includes Cluster Manager improvements under-the-hood as well. First off we attended to some long overdue maintenance by updating from Java 6 to Java 8. This required us to update many of the third-party libraries upon which the Cluster Manager is built, which in turn prompted a variety of source code changes to account for changes in APIs — affecting about 26% of the Java classes in our implementation. For now the primary benefit of this work is improved stability and reliability as we pulled in fixes in those third-party libraries. But in future releases, the groundwork we’ve done in 9.1 will enable us to take advantage of modern language features in Java 8, and to use new third-party Java integrations that have been introduced in the past few years.
The other major back-end change for the Cluster Manager is that it now runs on top of a 64-bit JVM. This enables the CM to more easily manage the large, busy clusters that some users wish to deploy — thousands of agents with hundreds of concurrent builds, with tens of millions of builds executed over the lifetime of the deployment.
Licensing updates
Finally, Accelerator 9.1 includes some changes to the way the product is licensed based on our experience with ElectricAccelerator Huddle, the freemium/low-end version of Accelerator that’s been in public beta for a few years. For small-to-medium-sized teams, Accelerator can be licensed by number of agents and number of concurrent builds, at a price point that I think users will find very reasonable (unfortunately I can’t disclose specific numbers here).
In addition, management of so-called “local agents” has been drastically simplified, again based on our experience with Huddle. To put it simply: local agents — any agent that is running on the same host as emake itself during a build — are now managed via the Cluster Manager, just like any other agent in the cluster. Both the CM and emake will prefer to allocate and use local agents when possible, as these tend to give better performance by avoiding network overhead.
Availability
ElectricAccelerator 9.1 is available immediately for current users via the Electric Cloud ShareFile site. For new users, contact sales@electric-cloud.com for a demo or eval download. Upgrading is recommended for all users.
As always, this release would not have been possible without the outstanding efforts of the ElectricAccelerator Engineering team at Electric Cloud. Thank you all for your contribution!