Recently a customer asked me to help them create a list of factors that affect build performance. They found themselves often tasked with explaining to their developers why one build had worse performance than another, or with finding ways to further improve the performance of a build. This is a very big, very complex question — I think perhaps much more so than they realized at first! In fact I think the question as posed is fundamentally unanswerable: I could never give an exhaustive list of the factors that affect build performance. There are too many, and there are surely some that I myself have yet to see — “unknown unknowns” as they say.
Nevertheless, there is value in making a list, even if incomplete, if for no other reason then to serve as a reference for people trying to understand or improve the performance of their builds. What follows is my attempt at creating that list, roughly in order of importance — but bear in mind that this ordering is somewhat subjective, and highly situation-dependent: your mileage may vary, and different builds will have different specific bottlenecks.
Factors that affect build performance
- Build size
Builds can be measured in many ways: number of output targets, number of input files, total lines of code, aggregate bytes of output generated, etc. Generally speaking, the bigger the build is, the longer it will take to complete. If your build is long simply because of its size, you may think you have no opportunities, but that’s not so: parallel builds, caching outputs, componentization and beefier hardware can all help cope with this type of problem.
- Execution parallelism
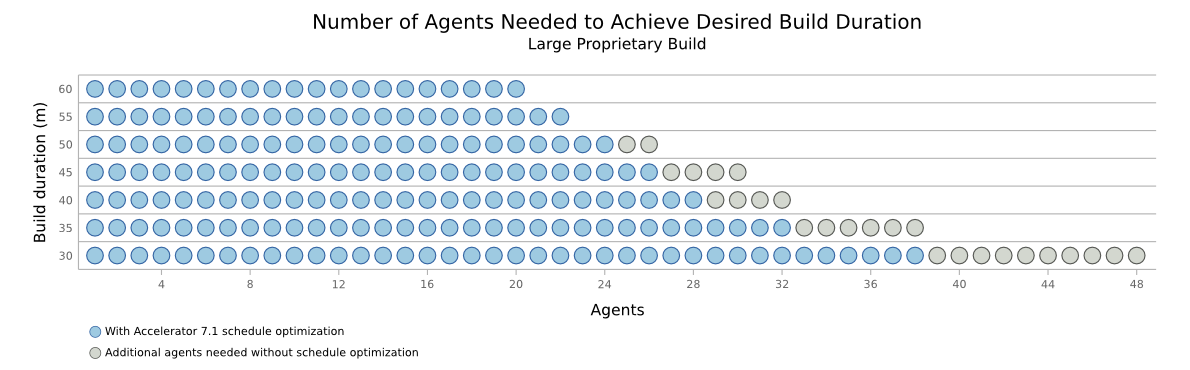
Most build tools support some form of parallel execution — GNU make’s -j option is the classic example. Assuming there is parallelizable work in the build, the build that runs on more cores (that is, with a higher -j value) will complete more quickly.
- Available parallelism / build structure
Running a build on many cores only helps if there is exploitable parallelism in the build. If the build is defined in such a way that parallelism is limited, then it will take longer to complete regardless of the -j value. For example, some builds may have unnecessary serializations in the dependency graph, which will limit performance.
- Caching
The use of (or failure to use) caching technology, such as ElectricAccelerator’s JobCache, ClearCase winkins, or ccache, can dramatically impact build performance. In my tests caching such as JobCache can reduce build duration by 50% or more for full builds.
- Conflicts (ElectricAccelerator only)
For builds executed with ElectricAccelerator, conflicts can have a significant impact on performance. Briefly, an Accelerator conflict is any time your build “loses” a race condition between two steps that should have been serialized but weren’t due to missing dependencies in your makefile or build files. Accelerator can detect and correct such errors on-the-fly, but it comes at a cost. A few conflicts is usually not a problem, but if you have hundreds or thousands, it will make your build slower as Accelerator reruns portions of the build to get the correct results. Usually if you see such a scenario it’s a sign that you didn’t have a complete Accelerator history file for your build, so fixing such issues is as easy as using the history file generated by that build to augment the dependency information in future runs of the build.
- Code complexity and structure
There are many attributes of the code itself which can affect build performance. For example, as a general rule, very long source files will take longer to compile than shorter files. Files containing very long individual functions will take longer to compile than files with only short functions. Heavy use of templates in C++ will cause slower compilation. Careless use of #include statements in C or C++ code will cause slower compilation and can be especially harmful to incremental builds by triggering excessive recompilation.
- Implementation language
Some languages are easier to process and therefore faster to compile. In general, C++ is slower to compile, while languages like Java or Go are very quick to compile. Some languages require no compilation at all, so builds of code using such languages can be very very fast indeed!
- Build tool
There are a staggering array of build tools which you might choose to drive your build: GNU make, ninja, maven, ant, scons, emake, tup and more. Some were designed for high performance on full builds, while others were designed for high performance on incremental builds, and still others were designed for ease-of-use, correctness, or other non-performance related attributes. The choice of build tool will affect the performance of your build, especially if your build is very large.
- Compiler
For compiled languages like C and C++ there are often many different compilers that you could choose from for your build: gcc/g++, clang, icc, WindRiver, Microsoft cl, tcc, etc. These tools themselves have different performance profiles, and the performance may even vary from one version of the compiler to the next.
- Compiler options
For a given compiler, the build options you enable may significantly affect the compile time. For example, when using gcc, building with -O3 is generally slower than building with -O0. Therefore for developer builds, you may consider to disable optimizations in order to reduce build cycle time. Other options that may influence compile speed include: pre-compiled headers (PCH); dependency generation (-MD, -MMD, -MF, etc); profiling or coverage analysis (-fprofile-arcs or -ftest-coverage); and include path definitions (-I), which if very long can cause the compiler to spend excessive time searching for header files.
- Linker
As with the compiler, different linkers have different performance characteristics. For C/C++ compilation on Linux the default linker is GNU ld, but there are alternatives like Google gold which have much better performance, albeit for a subset of the use cases supported by GNU ld. If your use case is supported by gold, you will likely see much better build performance by switching.
- Memory
As with any process involving computers, the amount of available memory will have a significant impact on build performance. Too little and your system will swap excessively. Fortunately there’s no such thing as “too much”, though it may be prohibitively expensive to get so much RAM that you can stop worrying about it. In practice most builds do not require a huge amount of memory, but if yours do, and you don’t have enough, your build speed will suffer.
- Disk performance
Like memory, the performance of your disk can significantly affect build performance. In fact its easier in some ways to understand the impact of disk speed. If the build generates 10GB of output and your disk can only write at 10MB/s, the fastest that the build can possibly finish is about 1,000 seconds, or nearly 20 minutes. On the other hand, if the build generates only 5MB of output and uses the same disk, then only 1/2 second is needed to write the build outputs, so the disk is unlikely to be a bottleneck. You may find that the disk is adequate for your builds now, but as the build gets bigger you will reach a point where the disk is no longer fast enough. At that point you can upgrade to a faster disk, and that will be sufficient for some time until again your build grows to exceed the capacity of the disk.
Even if your disk is not a primary bottleneck now, switching to a faster disk may improve performance somewhat. Many users have had good results from switching to SSD for temporary storage, or using striped RAID for those builds that generate truly enormous amounts of data.
- Network performance
For distributed builds such as those executed with ElectricAccelerator, network performance is crucial because build data has to be transferred across the network. But even if the build itself is not distributed, it may make use of tools pulled from a network file share, so the network performance can affect the build.
- Operating system / kernel version
Some operating systems have better performance for builds than others — in general, I’ve found builds on Linux to be relatively faster than builds on Windows, for example. Likewise, some versions of the operating system may be faster than others. Some users have reported as much as a 3x improvement by upgrading from an old version of Linux to a newer version due to optimizations in the kernel itself.
- Anti-virus software
Use of anti-virus software can dramatically impact build performance, particularly if the A/V is configured in one of the more aggressive or intrusive modes of operation: sometimes every file operation is intercepted by the A/V scanner, adding a substantial drag on build speed.
- License management
Some build tools, such as certain commercial compilers, require licenses in order to operate. If the license system is misconfigured it can add delays to the build process, sometimes causing each compile to take minutes instead of seconds as the compiler tries and fails to contact a license server, or contacts the wrong license server instance (for example, one on a different subnet).
A foundation for performance investigations
So there you have it: my (not entirely) comprehensive list of factors that can affect build performance. Of course these won’t all be relevant for every build: every build is different, and each has a unique performance profile. A slow disk may be mostly irrelevant for one build but absolutely critical for another. My hope is that this list will serve as a foundation for your build performance investigations — something to help get you started, even if it doesn’t get you all the way to a conclusion.
What do you think of my list? What would you add, and how would you change the ordering? Let me know in the comments below.