Recursive make is one of those things that everybody loves to hate. It’s even been the subject of one of those tired “… Considered Harmful” diatribes. According to popular opinion, recursive make will sap performance from your build, make it nigh impossible to ensure correctness in parallel builds, and may render the user sterile. OK, maybe not that last one. But seriously, the arguments against recursive make are legion, and deeply entrenched. The problem? They’re flawed. That’s because they assume there’s only one way to implement recursive make — when the submake is invoked, the parent make is blocked until the submake completes. That’s how almost everybody does it. But in Electric Make, part of ElectricAccelerator, we developed a novel new approach called non-blocking recursive make. This design eliminates the biggest problems attributed to recursive make, without requiring a painful and costly conversion of your build system to non-recursive make.
The problem with traditional recursive make
There’s really just two problems at the heart of complaints with traditional recursive make: first, there’s no way to ensure correctness of a parallel recursive make based build without overserializing the submakes, because there’s no way to articulate dependencies between individual targets in different submakes. That means you can’t have a dependency graph that is both correct and precise. Instead you either leave out the critical dependency entirely, which makes parallel (ie, fast) builds unreliable; or you serialize submakes in their entirety, which shackles build performance because no part of a submake with even a single dependency on some portion of an earlier submake can begin until the entire ealier submake completes. Second, even if there were a way to specify precise dependencies between targets in different submakes, most versions of make have implemented recursive make such that the parent make is blocked from proceeding until the submake has completed. Consider a typical use of recursive make with implicit serializations between submakes:
|
1
2
3
4
|
all:
@for dir in util client server ; do \
$(MAKE) -C $$dir; \
done
|
Each submake compiles a bunch of source files, then links them together into a library (util) or an executable (client and server). The only actual dependency between the work in the three make instances is that the client and server programs need the util library. Everything else is parallelizable, but with traditional recursive make, gmake is unable to exploit that parallelism: all of the work in the util submake must finish before any part of the client submake begins!
Conflict detection and non-blocking recursive make
If you’re familiar with Electric Make, you already know how it solves the first half of the recursive make problem: conflict detection and correction. I’ve written about conflict detection before, but here’s a quick recap: using the explicit dependencies given in the makefiles and information about the files accessed as each target is built, emake is able to dynamically determine when targets have been built too early due to missing explicit dependencies, and rerun those targets to generate the correct output. Electric Make can ensure the correctness of parallel builds even in the face of incomplete dependencies, even if the missing dependencies are between targets in different submakes. That means you need not serialize entire submakes to ensure the build will run correctly in parallel.
Like an acrobat’s safety net, conflict detection allows us to consider solutions to the other half of the problem that would otherwise be considered risky, if not outright madness. In fact, our solution would not be possible without conflict detection: non-blocking recursive make. This is analogous to the difference between blocking and non-blocking I/O: rather than waiting for a recursive make to finish, emake carries on executing subsequent commands in the build immediately, including other recursive makes. Conflict detection ensures that only the commands in each submake which require serialization are executed sequentially, so the build runs as quickly as possible, but the final build output is identical to a serial build.
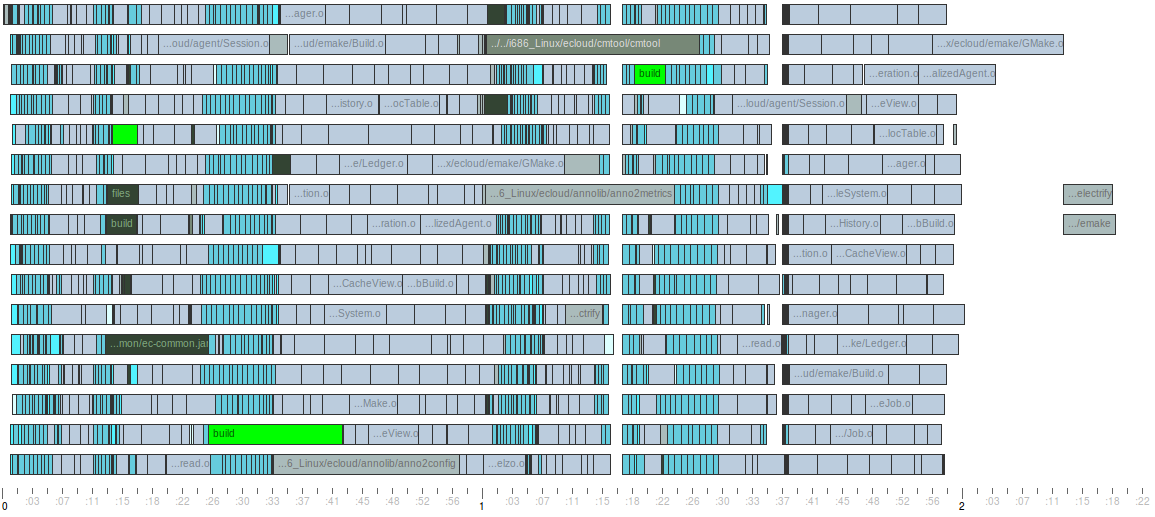
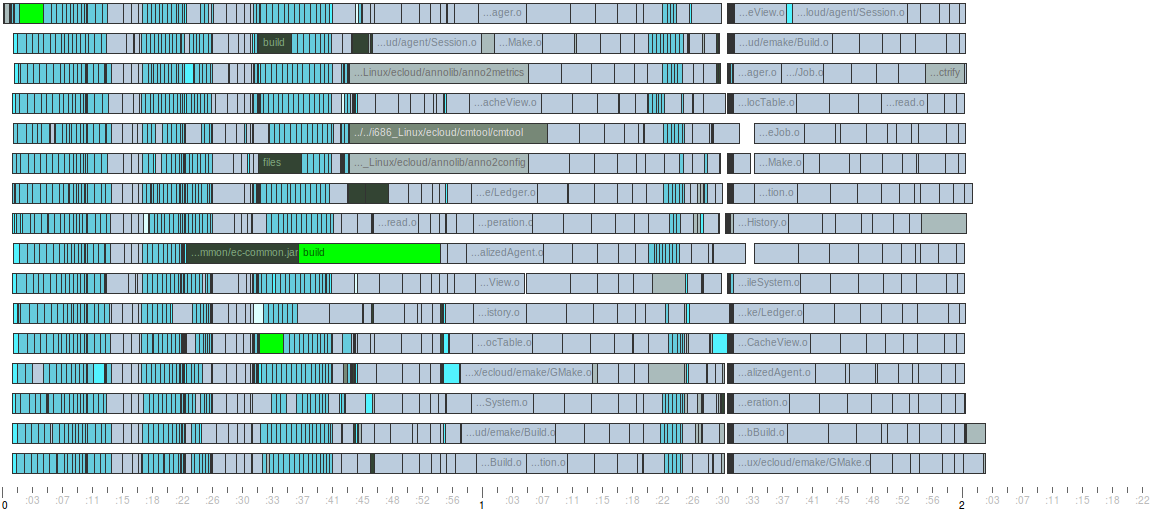
The impact of this change is dramatic. Here I’ve plotted the execution of the simple build defined above on four cores, using both gmake (normal recursive make) and emake (non-blocking recursive make):

Recursive make build with gmake

Recursive make build with emake
Electric Make is able to execute this build about 20% faster than gmake, with no changes to the Makefiles or the execution environment. emake is literally able to squeeze more parallelism out of recursive-make-based builds than gmake. In fact, we can precisely quantify just how much more parallelism emake gets through an application of Amdahl’s law. First, we compute the best possible speedup for the build — that’s just the serial runtime divided by the best possible parallel runtime, which we can figure out through analysis of the depedency graph and runtime of individual jobs in the build (the Longest Serial Chain report in ElectricInsight can do this for you). Then we can compute the parallelizable portion P of the build by plugging the speedup S into this equation: P = 1 – (1 / S). Here’s how that works out for gmake and emake:
|
gmake |
emake |
| Serial baseline |
65s |
65s |
| Best build time |
13.5s |
7.5s |
| Best speedup |
4.8x |
8.7x |
| Parallel portion |
79% |
89% |
On this build, non-blocking recursive make increases the parallel portion of the build by 10%. That may not seem like much, but Amdahl’s law shows how dramatically that difference affects the speedup you can expect as you apply more cores:

Implementation
On the backend, non-blocking recursive make is handled by conflict detection — the jobs from the recursive make are checked for conflicts in the serial order defined by the makefile structure. Any issues caused by aggressively running recursive makes early are detected during the conflict check, and the target that ran too early is rerun to generate the correct result.
On the frontend, emake uses a strategy that is at once both brilliant in its simplicity, and diabolical in its trickery. It starts with an environment variable. When emake is invoked recursively, it checks the value of EMAKE_BUILD_MODE. If it is set to node, emake runs in so-called stub mode: rather than executing the submake (parsing the makefile and building targets), emake captures the invocation context (working directory, command-line and environment) in a file on disk, prints a “magic” string and exits with a zero status code.
The file containing the invocation context is identified by a second environment variable, ECLOUD_RECURSIVE_COMMAND_FILE. The Accelerator agent (which handles invoking commands on behalf of emake) checks for the presence of that file after every command that is run. If it is found, the agent relays the content to the toplevel emake invocation, where a new make instance is created to represent the submake invocation. That instance comes with it’s own parse job of course, which gets inserted into the queue of jobs. Some (short) time later, the parse job will run, discover whatever work must be run by the submake, and create additional rule jobs.
The magic string — EMAKE_FNORD — serves as a placeholder in the stdout stream for the jobs, so emake can figure out which portion of the output text comes before and which portion comes after the submake. This ensures that the build output log is identical to that generated by a serialized gmake build. For example, given the following rule that invokes a submake, you’d expect to see the “Before” and “After” messages printed before and after the output generated by commands in the submake itself:
|
1
2
3
4
|
all:
@echo Before util ; \
@$(MAKE) -C util ; \
@echo After util
|
With non-blocking recursive make, the submake has not actually executed when the “echo After util” command runs. If emake doesn’t account for that reordering, both the “Before” and “After” messages will appear before any of the output from the submake. EMAKE_FNORD allows emake to “stitch” the output together so the build log matches a serial log.
Limitations
Conflict detection and non-blocking recursive make together solve the main problems associated with recursive make. But there are a couple scenarios where non-blocking recursive make does not work well. Fortunately, these are uncommon in practice and easily addressed.
Capturing recursive make stdout
The first scenario is when the build captures the output of the recursive make invocation, rather than letting it print to stdout as normal. Since emake defers the execution of the submake and prints only EMAKE_FNORD to stdout, this will not work. There are two reasons you might do this: first, you might want to have separate build logs for each submake, to simplify error detection and management. In this situation, the simplest workaround is to remove the redirection and instead us emake’s annotated build log, an XML version of the build output log which can be easily processed using standard tools. Second, you may be using make as a text-processing tool (sort of a “poor man’s” Perl), rather than for building per se:
|
1
2
3
|
all:
@$(MAKE) -f genlist.mk > objects.txt
@cat objects.txt | xargs rm
|
In this case, the workaround is to explicitly force emake to run in so-called “local” mode, which means emake will handle the recursive make invocation as a blocking invocation, just like traditional make would. You can force emake into local mode by adding EMAKE_BUILD_MODE=local to the environment before the recursive make invocation.
Immediate consumption of build products
The second scenario is when the build consumes the product of the submake in the same command that contains the invocation. For example:
|
1
2
|
all:
@$(MAKE) -C sub foo && cp sub/foo ./foo
|
Here the build assumes that the output files generated by the submake will be available for use immediately after the submake completes. Obviously this is not the case with non-blocking recursive make — when the invocation of $(MAKE) -C sub foo completes, only the submake stub has actually finished. The build products will not be available until after the submake is actually processed later. Note that in this build both the recursive make invocation and the commands that use the build products from that invocation are treated as a single command from the perspective of make: make actually invokes the shell, and the shell then runs the recursive make and cp commands.
The workaround is simple: split the consumer into a distinct command, from the perspective of make:
|
1
2
3
|
all:
@$(MAKE) -C sub foo
@cp sub/foo ./foo
|
With that trivial change, emake is able to treat the cp as a continuation job, which can be serialized against the completion of the recursive make as needed.
A fix for recursive make
For years, people have heaped scorn and criticism on recursive make. They’ve nearly convinced everybody that even considering its use is automatically wrong — you probably can’t help feeling a little bit guilty when you use recursive make. But the reality is that recursive make is a reasonable way to structure a large build. You just need a better make. With conflict detection and non-blocking recursive make, Electric Make has fixed the problems usually associated with recursive make, so you can get parallel builds that are both fast and correct. Give it a try!