What’s new in CloudBees Build Acceleration 12.0?
Just in time for the new year, this month we released CloudBees Build Acceleration 12.0, the 40th feature release of the product previously known as CloudBees Accelerator and before that ElectricAccelerator. This is possibly the most significant update for most end users since the 8.0 release in 2015, thanks to a massive overhaul and expansion of the Build Details page in the Cluster Manager that puts metrics, visualization and even recommendations just a click away in your browser. We also improved jobcache, by adding context-sensitive hashing for C/C++ source files — no more cache misses when you change comments! — as well as content-sensitive hashing for Unix archives, and support for caching Kotlin compilation. Finally, we added an enhancement to our GNU make emulation to automatically create output directories: no more need for messy order-only prereqs or sentinel files or mkdir -p $(dirname $@) all over your makefiles. Keep reading for screenshots and more details.
Build Details
The improvements I’m most excited about in Build Acceleration 12.0 are the sweeping updates to the Build Details page in the Cluster Manager. These are designed to give you access to build visualization and performance analysis, right from the comfort of the browser. Much of this functionality has been available for a long time as part of Insight, a desktop application for build visualization and analysis, but we found that few users took advantage of that functionality. We hope that by automatically collecting the data and providing it via the Cluster Manager web interface, more users will be able to leverage that analysis not only to see the benefit they derive from using Build Acceleration, but to better monitor and improve performance. The update consists of a redesigned UI framework for the Build Details page, as well as several new or enhanced sub-tabs:



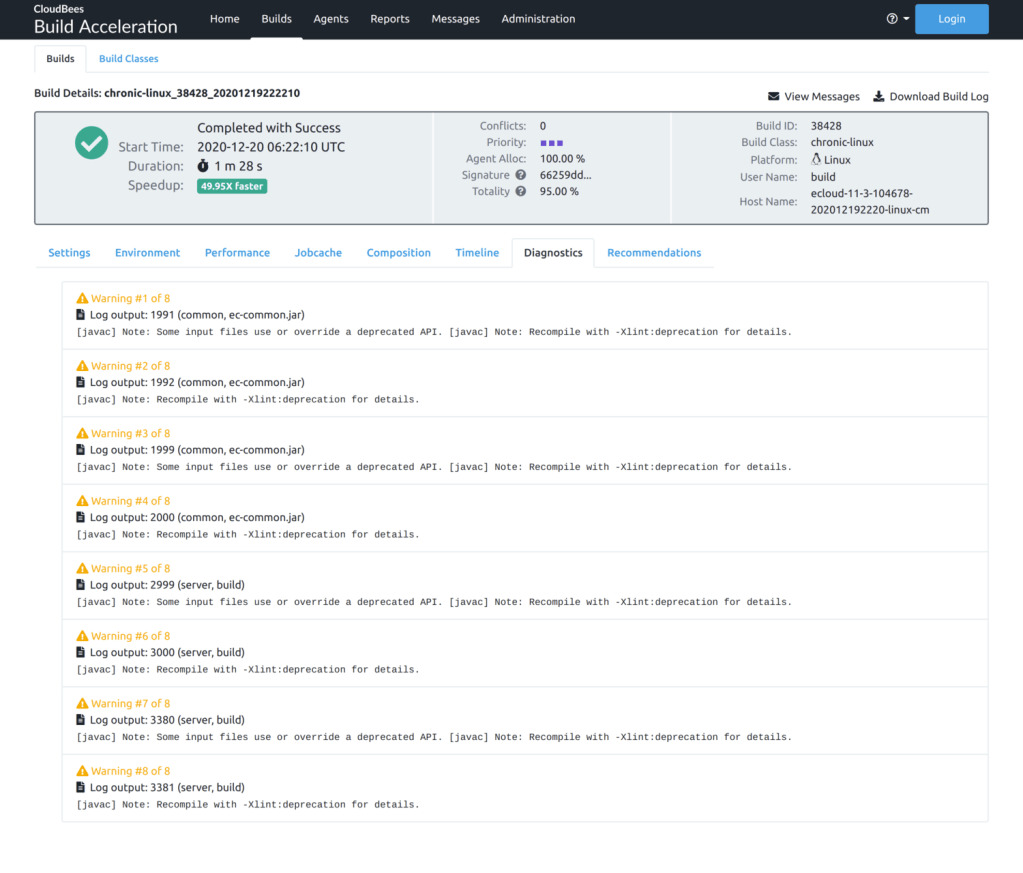
- The Settings tab shows both the user-specified options used in the build, as well as any other properties determined by emake itself, like the OS version and others.
- The Environment tab shows the environment variables in effect when emake was invoked.
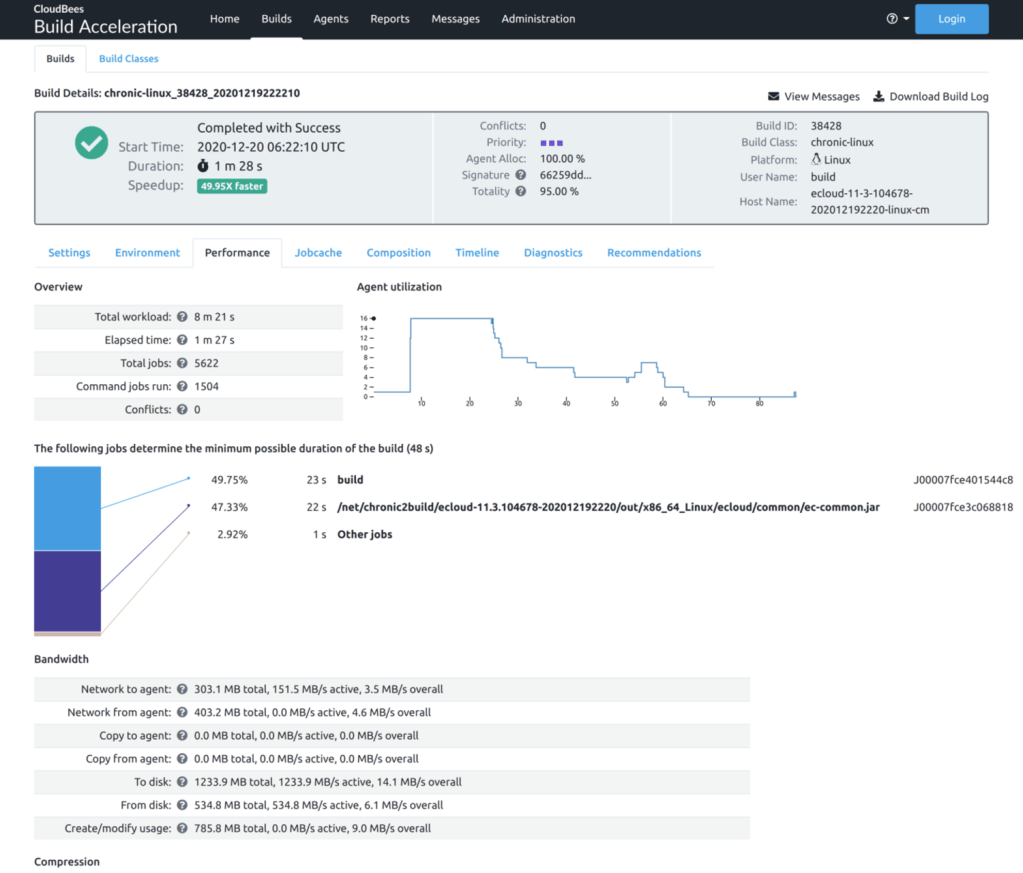
- The Performance tab shows dozens of individual performance metrics, such as network and disk bandwidth and compression performance, as well as the number of agents in use over the duration of the build and the critical path through the build, or the serialized set of jobs that determines the minimum possible duration of the build.
- The Jobcache tab shows metrics relating to the use of jobcache in the build, including the overall cache hit rate, the estimated time saved due to caching, and the specific types of jobcache used. You can also find the portion of the total build workload that was cached.
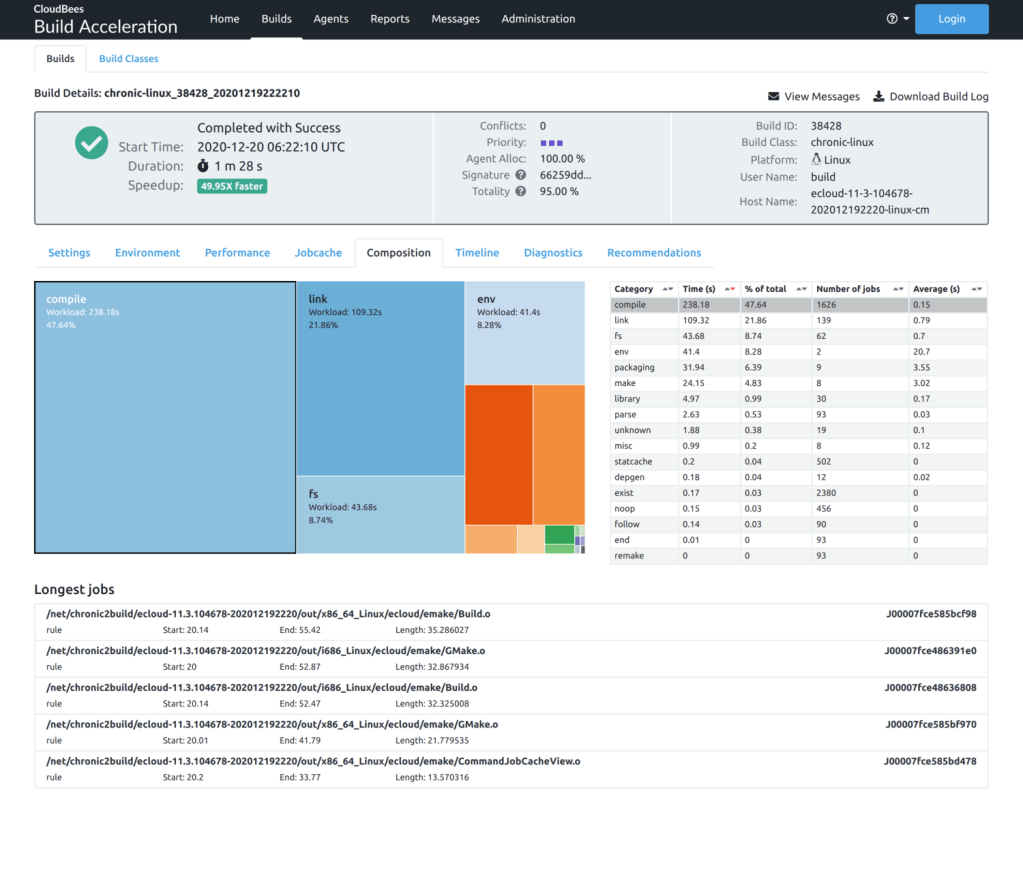
- The Composition tab shows a breakdown of the work performed during the build according to the semantic classification of that work, such as compilation, linking, or packaging. Clicking on any of the categories shows the longest jobs in the build belonging to that category.
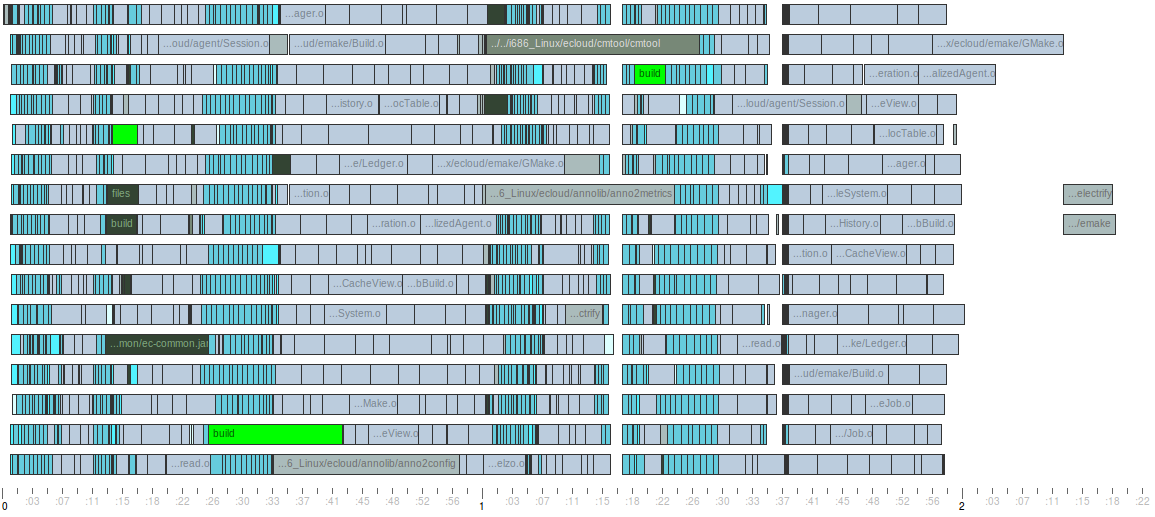
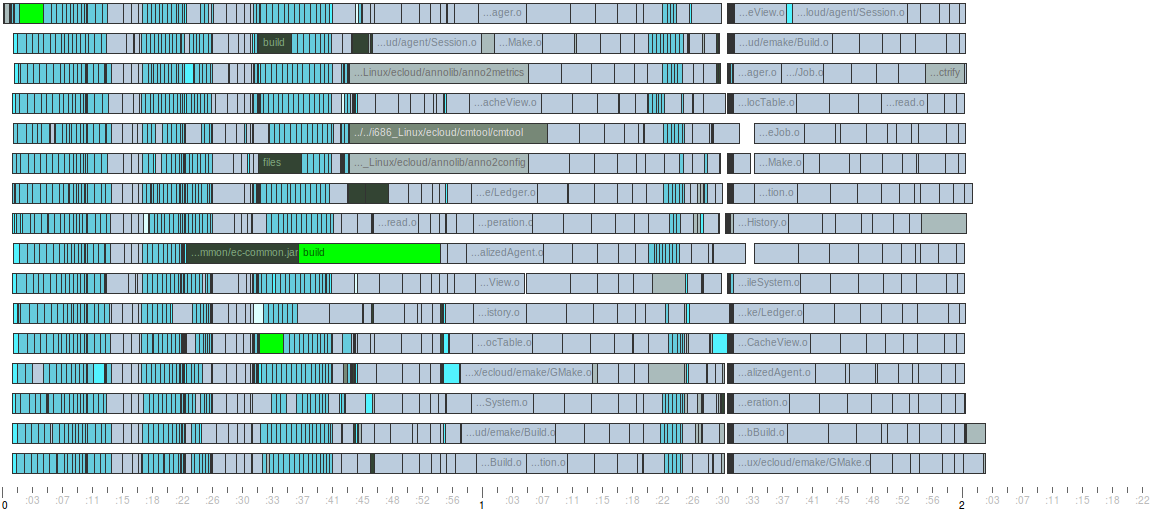
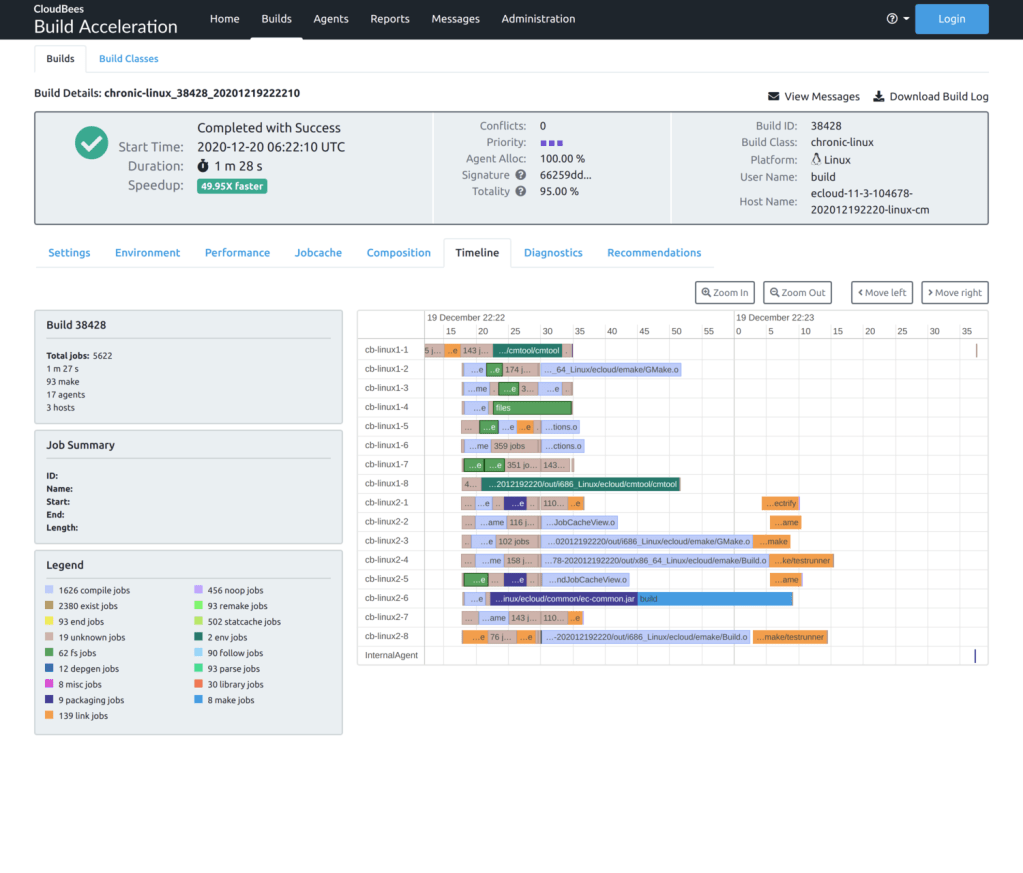
- The Timeline tab shows a visualization of the build’s execution. For efficiency reasons (both in terms of rendering and backend storage) detailed information is only available for non-trivial jobs in the build. Shorter jobs are aggregated into blocks so they can still be seen in this visualization. If you want to see more details than are available in this visualization, you can run CloudBees Build Acceleration Insight on the annotation file from the build.
- The Diagnostics tab presents warnings and error messages culled from the build output log, using analysis similar to that found in CloudBees CD (formerly ElectricFlow).
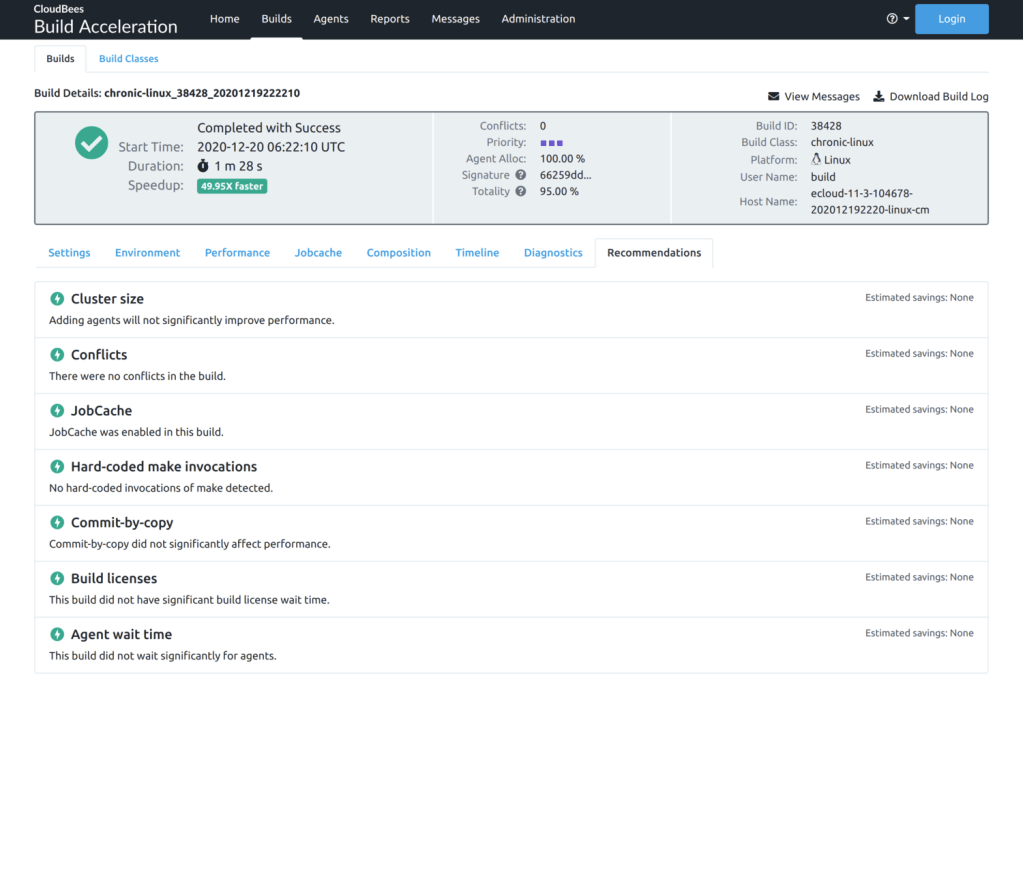
- Finally, the Recommendations tab presents suggestions for ways to improve build performance and an estimate of the impact of implementing those suggestions. The list is prioritized according to that estimate. Of course this is not an exhaustive list of ways to improve performance — instead, you should see these recommendations as a starting point for build optimization. Today the report checks for several common types of performance gotchas; in the future we hope to add more.
If you’ve used Build Acceleration Insight in the past, some of the information you’ll find in the Build Details page now will seem familiar. The nice thing is that you no longer have to manually remember to run Insight, and you can access this analysis from any browser that can access the Cluster Manager, even for builds that were run on different hosts and for which the annotation file may not be available. I truly believe that having this information easily accessible will enable more users to “self serve” when it comes to performance analysis, effectively making everybody a Build Acceleration “super user”.
Note: in order to use the new Build Details, you must upgrade both the Cluster Manager and emake to 12.0 or later. Enhanced analysis is not available for builds run using older versions of emake.
Build Signature and Totality
Tucked into the Build Details screenshots above you may have noticed a couple additional fields in the header: signature and totality. These new build properties make it possible to identify builds that are building the same stuff, and whether a build is full or incremental:

The signature is simply a hash of the names of all the output targets in the build, in serial order. If you run the same build repeatedly, you should get the same signature for each run. If you add or remove modules or targets in the build, the signature will change. If the builds are entirely different, such as of different packages, the signatures will be different.
The totality of the build reflects the percentage of rule jobs in the build that were determined to be out-of-date during the run. In theory a full-from-scratch build will have a totality of 100%, although many builds have duplicate targets and other quirks that result in the totality being less than that even for a full-from-scratch build. Each build is unique, so you’ll have to observe the behavior of this value in your own builds to know what is normal for your configuration. Conversely, a “no touch” build should have a totality of 0%, but again many builds have rules that are always run, so even in a “no touch” build the totality is not quite 0%. Again, you’ll have to observe the behavior in your builds to understand what is normal for your configuration. In general comparing totality from dissimilar builds (that is, those that have a different signature) is not useful, but you can use it to distinguish full (or mostly full) builds from incremental or no touch builds when the signatures are the same. Remember too that totality is a continuum: if 100% is a full-from-scratch build and 0% is a no touch build, an incremental that rebuilds only a few outputs might have a totality of 10% or 20%, while an incremental that rebuilds many outputs might have a totality of 70% or 80%.
JobCache Enhancements
CloudBees Build Acceleration 12.0 also includes several improvements to the jobcache feature to improve performance, increase cache hit rates and expand the types of work that can be cached. Chief among these is an intelligent hasher for C/C++ source code, which enables emake to ignore comments and blank lines in those files when determining whether an input has changed. That means that these two fragments are considered equivalent:
/* Generated 2020-DEC-15 11:57:32 */
#include "util.h"
static const int DEBUG = 1;/* Generated 2020-DEC-18 15:12:47 */
#include "util.h"
static const int DEBUG = 1;Previously a change like this would have caused a jobcache miss — technically correct, but unfortunate since obviously the code in question has not actually changed in a meaningful way. With this enhancement, emake correctly recognizes that fact, and you’ll get a jobcache hit (assuming no other changes, of course).
Along the same lines, we added an intelligent hasher for Unix archive files — .a or .la files. In this case, emake now knows to ignore the timestamps embedded in the archive, while still considering the content of the members of the archive. Again this allows for a greater number of cache hits in practical usage.
Next, we extended the javac jobcache type so it applies to Kotlin compilation in addition to Java compilation. Kotlin is a programming language that is used extensively in the Android ecosystem, and which is interoperable with Java — in fact in most cases Kotlin is compiled into Java byte code. Expanding the scope of jobcache to include Kotlin enables caching of even more work in Android system builds.
Finally, in this release we changed how emake stores timestamp data in jobcache entries. Previously, if a cached job set an explicit timestamp on a file (something like touch -t 202012010000 foo), that timestamp would be recreated precisely as it was saved in the cache, even if the cache was used days or months after it was originally initialized. That lead to some surprising behaviors, because running a build today might result in build outputs with a timestamp from some time far in the past. In turn that caused unwanted rework in incremental builds, because some timestamps were very old, but others (from outputs created by uncached jobs, for example) were current. With this change, emake no longer saves explicit timestamp modifications in the jobcache, so outputs pulled from the cache are always given a timestamp reflecting the time at which the outputs were created in the current build.
Automatically creating output directories
Although there are many other improvements in the 12.0 release, there’s one more in particular that I think warrants a mention, because it directly addresses a problem that many make users contend with: how to efficiently, succinctly, and correctly create parent directories for output targets in the build. This is a topic that has been written about often and which should be familiar to anybody who’s had to maintain a make-based build. Essentially the question is: how can we make sure the directories for outputs in a makefile will be created before the outputs themselves are created? Of course if you fail to create the directories, the build will fail. It’s true there are a variety of ways to solve this in GNU make, but truthfully they are all kind of clunky, requiring some combination of redundant mkdir commands (which waste time), or sentry files (which create clutter), or for the user to remember to add extra prereqs all over the place. Other build tools, like ninja, have a pretty tidy solution: the build tool itself just automatically creates the output directory just before it is needed. This is clean, simple, and efficient — and now, if you use emake, you can get the same behavior for your make-based build by adding --emake-create-output-dirs=1 to your invocation. In this mode, emake will automatically create special jobs to handle making output directories in the most efficient possible way, with no makefile modifications required.
Availability
As you can see, I’m pretty excited about the 12.0 release of CloudBees Build Acceleration. I can’t wait to see how people make use of the new Build Details information to understand and optimize their builds, and I’m always amazed that even after 40 releases we’re still finding ways to make builds faster than ever. I hope you’ll upgrade soon.
CloudBees Build Acceleration 12.0 is available immediately for current users, and new users can download a free trial.